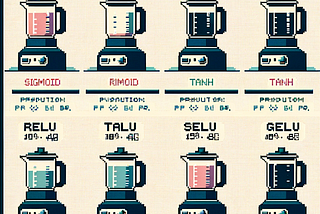
PinnedPublished inTDS ArchiveCourage to Learn ML: Tackling Vanishing and Exploding Gradients (Part 2)A Comprehensive Survey on Activation Functions, Weights Initialization, Batch Normalization, and Their Applications in PyTorchMay 3, 2024May 3, 2024
PinnedPublished inHuman PartsAn Unfiltered Review of My Parenting So FarAnd it’s been good.Feb 29, 202412Feb 29, 202412
PinnedPublished inTDS ArchiveCourage to Learn ML: A Detailed Exploration of Gradient Descent and Popular OptimizersAre You Truly Mastering Gradient Descent? Use This Post as Your Ultimate CheckpointJan 9, 20246Jan 9, 20246
Keep Learning Like the AI Models DoAfter being a TA at OMSCS for nearly four years, this is what I wish every ML learner could hearMar 17Mar 17
Why I’m Taking a Step Back from Medium: Three Big Reasons and What’s Coming NextI’m Not Quitting — Just Moving to a New Home! All My Medium Posts Stay, and My Future Writing Is Free. Come Join Me on Layers of Curiosity!Feb 9Feb 9
Published inTDS ArchiveMy learning to being hired again after a year… Part IFor anyone job hunting, not just tech folksJun 23, 20245Jun 23, 20245
Published inTDS ArchiveCourage to Learn ML: Tackling Vanishing and Exploding Gradients (Part 1)Melting Away DNN’s Gradient Challenges: A Scoop of Solutions and InsightsFeb 5, 20241Feb 5, 20241
Published inTDS ArchiveCourage to Learn ML: Explain Backpropagation from Mathematical Theory to Coding PracticeTransforming Backpropagation’s Complex Math into Manageable and Easy-to-Learn BitesJan 17, 20241Jan 17, 20241
Published inTDS ArchiveCourage to Learn ML: An In-Depth Guide to the Most Common Loss FunctionsMSE, Log Loss, Cross Entropy, RMSE, and the Foundational Principles of Popular Loss FunctionsDec 28, 2023Dec 28, 2023
Relax Your Butt and Be Gentle with YourselfMy Personal Tale and a Heartfelt Message to the Recently Laid OffDec 18, 2023Dec 18, 2023